Knime, the open-source data analytics platform, isn’t your grandpappy’s spreadsheet software. It’s a visual workflow builder that lets you drag-and-drop your way to insightful data analysis, machine learning models, and killer visualizations. Think of it as LEGOs for your data – you can build anything you want, from simple data cleaning to complex predictive models, all without writing tons of code.
Seriously, it’s that intuitive.
This guide dives into Knime’s core functionality, exploring its versatile node system, powerful extensions, and seamless integrations with other tools. We’ll cover everything from basic data wrangling and visualization to advanced machine learning techniques and workflow automation. Get ready to unlock the power of your data!
KNIME’s Core Functionality

KNIME, the Konstanz Information Miner, is a powerful open-source platform for data analytics. Its visual, workflow-based approach makes complex data manipulation and machine learning tasks surprisingly accessible, even for users without extensive programming experience. This ease of use, combined with its robust capabilities, makes KNIME a popular choice across various industries.KNIME’s workflow architecture is based on connecting individual processing units, called nodes, to create a visual representation of the data analysis process.
This modular design offers several key advantages. Firstly, it promotes transparency and reproducibility; the entire workflow is clearly documented, making it easy to understand and repeat the analysis. Secondly, it facilitates collaboration; multiple users can contribute to and modify the same workflow. Finally, it allows for efficient reuse of components; individual nodes or entire sub-workflows can be easily integrated into new projects.
Node Types and Applications
KNIME offers a vast library of nodes categorized by their function. These nodes cover the entire data science lifecycle, from data ingestion and preprocessing to modeling and evaluation. Some common node types include:
- Source Nodes: These nodes read data from various sources like CSV files, databases, or web APIs. For example, a “CSV Reader” node imports data from a comma-separated value file, while a “Database Reader” node connects to a database to retrieve data.
- Data Manipulation Nodes: These nodes perform operations like filtering, sorting, aggregating, and transforming data. Examples include “Row Filter” (removes rows based on conditions), “Sorter” (sorts data based on specified columns), and “GroupBy” (groups data based on selected columns and calculates aggregates).
- Machine Learning Nodes: These nodes implement various machine learning algorithms. Examples include “Linear Regression,” “Random Forest,” “Support Vector Machine,” and many others. These nodes allow users to build predictive models from their data.
- Visualization Nodes: These nodes create visual representations of data, such as charts and graphs. This helps in understanding patterns and insights within the data. Examples include nodes for creating scatter plots, histograms, and bar charts.
- Preprocessing Nodes: These nodes handle essential data preparation steps like data cleaning, feature scaling, and handling missing values. Examples include “Missing Value” nodes (handling missing data using imputation or removal) and “Normalizer” nodes (scaling numerical features to a specific range).
Example Data Manipulation Tasks
Let’s consider a few common data manipulation tasks and how they’re performed using KNIME nodes:
- Removing Duplicate Rows: A “Uniqueness” node can be used to identify and remove duplicate rows from a dataset based on specified columns.
- Filtering Data Based on Conditions: A “Row Filter” node allows you to filter rows based on specific conditions, such as selecting only rows where a particular column value exceeds a certain threshold.
- Creating New Columns: A “Column Filter” node allows selection of specific columns and a “Math Formula” node can be used to create new columns based on calculations involving existing columns (e.g., creating a “Total Price” column by multiplying “Quantity” and “Unit Price”).
Simple KNIME Workflow for Data Preprocessing
Imagine we have a dataset for predicting house prices. This dataset might contain features like size, location, number of bedrooms, etc., and a target variable representing the house price. Before building a machine learning model, we need to preprocess the data. A simple workflow could look like this:
1. Data Input
A “CSV Reader” node reads the house price dataset.
2. Missing Value Handling
A “Missing Value” node imputes missing values using a strategy like mean imputation or k-NN imputation.
3. Feature Scaling
A “Normalizer” node scales numerical features (e.g., house size) to a standard range (e.g., 0-1) to prevent features with larger values from dominating the model.
4. One-Hot Encoding
A “One Hot Encoding” node converts categorical features (e.g., location) into numerical representations suitable for machine learning algorithms.
5. Data Partitioning
A “Partitioning” node splits the data into training and testing sets to evaluate the model’s performance.This workflow preprocesses the data, making it ready for training a machine learning model using nodes like “Linear Regression” or “Random Forest.” The output of this preprocessing workflow can then be fed into a modeling workflow. This modular approach allows for easy modification and experimentation with different preprocessing techniques.
KNIME Extensions and Integrations
KNIME’s power isn’t just in its core functionality; it’s also in its massive ecosystem of extensions and its seamless integration with other tools. This allows you to tailor KNIME to your specific needs and leverage the strengths of other platforms for a truly comprehensive data science workflow. Think of it like building with LEGOs – the core bricks are great, but the special pieces and add-ons are where the real creativity comes in.
This section dives into the world of KNIME extensions and integrations, showcasing how to expand KNIME’s capabilities and connect it to various data sources and external tools.
Popular KNIME Extensions and Their Functionalities
KNIME’s extensive extension library offers a wide array of tools to enhance its functionality. These extensions add support for specific data formats, algorithms, and integrations with other software. Choosing the right extension depends on your project’s specific requirements. For example, extensions exist to simplify handling specific file types (like specialized image formats) or to integrate with advanced machine learning libraries.
Some popular extensions include those providing advanced visualization options (like creating interactive dashboards), those that streamline specific data manipulation tasks (such as text mining or time series analysis), and those offering pre-built models or algorithms for various machine learning tasks. Many extensions are developed by the KNIME community and are freely available, demonstrating the collaborative nature of the platform.
KNIME’s Integration with R and Python
KNIME offers excellent integration with R and Python, two leading languages in data science. This allows users to leverage the extensive libraries and algorithms available in these languages directly within their KNIME workflows. This integration is achieved through dedicated nodes that execute R or Python code, allowing for seamless data exchange between KNIME and these scripting environments.
For example, you could use a Python node to train a complex deep learning model using TensorFlow or PyTorch, then seamlessly integrate the model’s predictions back into your KNIME workflow for further analysis or visualization. Similarly, you could use an R node to perform advanced statistical analysis using packages like ggplot2 for creating publication-quality graphics.
Connecting KNIME to Various Data Sources
KNIME provides a plethora of nodes for connecting to diverse data sources, making it a versatile tool for any data science project. This includes direct connections to various databases (like MySQL, PostgreSQL, and Oracle), cloud storage services (like AWS S3, Google Cloud Storage, and Azure Blob Storage), and other file formats (like CSV, Excel, JSON, and XML). This allows for easy data ingestion and manipulation regardless of where your data resides.
The process usually involves selecting the appropriate database or cloud storage connector node, specifying the connection parameters (such as username, password, and database name), and then executing the node to retrieve the data. KNIME handles the complexities of database interactions and data transfer, allowing users to focus on the analysis itself.
Workflow Demonstrating KNIME Integration with Python
Let’s illustrate KNIME’s Python integration with a simple example. Imagine we have a CSV file containing customer data, and we want to perform some basic data cleaning and analysis using Python’s Pandas library. We can create a KNIME workflow with the following steps:
- Data Input: Use a “CSV Reader” node to read the customer data from the CSV file.
- Python Scripting: Use a “Python Script (Jython)” node to execute a Python script. This script will use Pandas to perform data cleaning (e.g., handling missing values, removing duplicates). The script would receive the data from the previous node and return the cleaned data. A sample script might look like this:
import pandas as pddata = input_table # Data from the CSV Reader nodedata.dropna(inplace=True) #remove rows with missing valuesdata.drop_duplicates(inplace=True) #remove duplicatesoutput_table = data - Data Output: Use a “Table Writer” node to save the cleaned data to a new CSV file or use other nodes for further analysis (e.g., statistical analysis, machine learning).
This simple workflow demonstrates how easily you can incorporate Python code into a KNIME workflow, leveraging the strengths of both platforms for efficient data manipulation.
Data Wrangling with KNIME
Data wrangling, that often-overlooked but crucial step in any data science project, is where KNIME truly shines. It provides a user-friendly, visual interface to tackle the messy reality of real-world data, transforming it into the clean, consistent datasets needed for analysis and modeling. Think of it as the data spa treatment before your data gets to the party.
Data Quality Issues and Their Resolution
Poor data quality can derail even the best-designed analysis. Common issues include missing values, outliers, inconsistencies in data formats, and duplicate entries. KNIME offers a robust suite of nodes to address these problems. For example, the “Missing Value” node can impute missing data using various methods like mean, median, or mode imputation, or more sophisticated techniques like k-Nearest Neighbors.
Outliers can be identified using statistical methods (like the Z-score) and then handled by either removal or transformation. Inconsistencies in data formats are easily addressed using the “String Manipulation” nodes, allowing for standardized formatting. Duplicate rows can be efficiently removed using the “Row Filter” node.
Handling Missing Values
Missing data is a ubiquitous problem. A step-by-step approach in KNIME involves: 1) Identifying the extent and pattern of missingness using the “Missing Value” node’s statistics. 2) Choosing an imputation strategy based on the nature of the data and the amount of missingness. Simple imputation methods like mean/median/mode imputation are readily available. More advanced techniques, such as k-Nearest Neighbors imputation, are also accessible through various extensions.
3) Applying the chosen imputation method using the appropriate node. 4) Evaluating the impact of imputation on downstream analysis. For example, if you are imputing missing values in a dataset used for predictive modeling, it’s important to assess whether the imputation method introduces bias or affects the model’s performance.
Handling Outliers
Outliers can significantly skew statistical analyses. In KNIME, a typical workflow would start with: 1) Identifying outliers using visual inspection (scatter plots, box plots generated via the “Scatter Plot” or “Box Plot” nodes) or statistical methods (e.g., calculating Z-scores using the “Math Formula” node). A Z-score above a certain threshold (e.g., 3) often indicates an outlier. 2) Deciding on a handling strategy.
Options include removing outliers using the “Row Filter” node (based on the calculated Z-scores), transforming them using techniques like winsorization or log transformation (using the “Math Formula” node), or keeping them and acknowledging their presence in the analysis. 3) Assessing the impact of outlier handling on the results. Consider whether removing or transforming outliers alters the overall conclusions of the analysis.
For instance, removing outliers that are genuinely representative of the population may lead to inaccurate or incomplete insights.
Data Normalization and Standardization
Data normalization and standardization are crucial preprocessing steps to ensure that features have comparable scales, preventing features with larger values from dominating the analysis. KNIME provides several ways to achieve this: 1) Normalization (min-max scaling) scales features to a range between 0 and 1 using the “Normalizer” node. This is suitable when the distribution of the data is not necessarily Gaussian.
2) Standardization (Z-score normalization) transforms features to have a mean of 0 and a standard deviation of 1 using the “Normalizer” node, selecting the Z-score option. This is particularly useful when the data follows a normal distribution or when distance-based algorithms (like k-means clustering) are used. The choice between normalization and standardization depends on the specific data and the subsequent analysis.
Machine Learning in KNIME

KNIME’s intuitive interface and vast library of nodes make it a powerful platform for building and deploying machine learning models. Whether you’re a seasoned data scientist or just starting out, KNIME provides the tools to tackle a wide range of machine learning tasks, from simple linear regression to complex deep learning architectures. This section will delve into the capabilities of KNIME for machine learning, covering algorithm comparison, model building, evaluation, and best practices.
Comparative Analysis of Machine Learning Algorithms
KNIME offers a comprehensive suite of machine learning algorithms, categorized broadly into supervised and unsupervised learning. Supervised learning algorithms, such as linear regression, logistic regression, support vector machines (SVMs), decision trees, and random forests, are used for prediction tasks where the data includes labeled outcomes. Unsupervised learning algorithms, including k-means clustering and principal component analysis (PCA), are employed for tasks like data exploration and pattern discovery in unlabeled datasets.
The choice of algorithm depends heavily on the specific problem, the nature of the data (e.g., linear vs. non-linear relationships, size and dimensionality), and the desired outcome (e.g., prediction accuracy, interpretability). For example, decision trees are often preferred for their interpretability, while SVMs are known for their performance in high-dimensional spaces. Random Forests, an ensemble method, frequently delivers high predictive accuracy by combining multiple decision trees.
Building and Evaluating Machine Learning Models
Building a machine learning model in KNIME typically involves several steps. First, data is preprocessed and cleaned using various nodes. Then, a suitable algorithm is selected based on the problem and data characteristics. The chosen algorithm’s parameters (hyperparameters) might need adjustment for optimal performance. The data is then split into training and testing sets.
The training set is used to train the model, while the testing set provides an unbiased evaluation of its performance. KNIME offers a variety of nodes for model evaluation, providing metrics like accuracy, precision, recall, F1-score (for classification), and RMSE, R-squared (for regression). Visualizations, such as ROC curves and confusion matrices, help interpret model performance. Iterative refinement of the model, involving adjustments to preprocessing steps, algorithm selection, and hyperparameters, is common practice to improve performance.
Best Practices for Model Selection and Hyperparameter Tuning
Effective model selection and hyperparameter tuning are crucial for building high-performing machine learning models. Cross-validation techniques, like k-fold cross-validation, help prevent overfitting by training and evaluating the model on multiple subsets of the data. Grid search and random search are commonly used for hyperparameter tuning, systematically exploring different parameter combinations to find the optimal settings. However, more advanced techniques such as Bayesian optimization can be more efficient for high-dimensional hyperparameter spaces.
Regularization techniques, such as L1 and L2 regularization, can help prevent overfitting by penalizing complex models. Careful consideration of the evaluation metrics relevant to the specific problem is also critical. For example, in medical diagnosis, high recall (minimizing false negatives) might be prioritized over high precision.
KNIME Workflow for a Classification Task
Let’s consider a simple spam detection task as a classification example. The workflow would begin with importing a dataset containing email text and a label indicating whether each email is spam or not. Text preprocessing nodes would clean the text data (removing stop words, stemming, etc.). A feature extraction node (e.g., TF-IDF) would then convert the text into numerical features suitable for machine learning algorithms.
KNIME’s a pretty cool platform for data wrangling, right? But sometimes you need to visualize your data spatially, which is where integrating it with gis software comes in handy. Then you can bring those spatial insights back into your KNIME workflows for further analysis and modeling – it’s a powerful combo!
The data would be split into training and testing sets. A classification algorithm, such as a Random Forest or Support Vector Machine, would be trained on the training data. The trained model would then be used to predict the class labels for the testing set. Finally, evaluation nodes would calculate metrics such as accuracy, precision, and recall, and potentially generate a confusion matrix to visualize the model’s performance.
The entire process, from data import to evaluation, would be visually represented as a connected series of nodes within the KNIME workflow. The workflow could then be easily exported and deployed for use in a real-world spam detection system.
KNIME for Data Visualization
KNIME’s strength lies not just in its data manipulation prowess, but also in its surprisingly robust visualization capabilities. It offers a wide array of nodes for creating various chart types, allowing users to explore and communicate their data insights effectively, all within the familiar drag-and-drop interface. This eliminates the need for separate visualization software, streamlining the entire data analysis workflow.
Visualization Nodes in KNIME
KNIME provides a comprehensive suite of visualization nodes, categorized broadly into those that generate static images and those that create interactive visualizations. Static visualizations are ideal for reports and presentations, while interactive visualizations are perfect for exploratory data analysis. The choice depends on your specific needs and the level of interaction desired. For instance, the “View” node offers a quick preview of data, while more sophisticated nodes like “Scatter Plot” or “Bar Chart” generate detailed visualizations.
Other nodes, such as those integrated with JavaScript libraries, create web-based interactive dashboards.
Generating Various Chart Types
Creating different chart types in KNIME is straightforward. For example, to generate a bar chart showing the frequency of different categories in a dataset, you would use the “Bar Chart” node. Simply connect this node to the output of a data manipulation node (like a “Group By” node to aggregate data) and configure the chart’s axes to represent the categories and their frequencies.
For scatter plots, which are useful for visualizing relationships between two numerical variables, the “Scatter Plot” node performs the same function, allowing you to map the variables to the X and Y axes. Other nodes allow for the creation of line charts, pie charts, histograms, and many more, all with similar ease of use. The specific parameters for each node will vary depending on the chart type and the data being visualized.
Customizing Visualizations
KNIME’s visualization nodes offer a wide range of customization options to enhance clarity and interpretation. For example, you can change the chart’s title, axis labels, colors, and legends. You can also adjust the size and font of text elements, add annotations, and modify the overall layout. This level of control allows you to tailor the visualization to your specific needs and ensure that it effectively communicates your findings.
Consider using a consistent color scheme and labeling conventions to improve readability and maintain a professional appearance. Furthermore, adjusting aspects like the scale of axes, adding trend lines, or highlighting specific data points can greatly improve the understanding of the data being presented.
Interactive Visualization Workflow
Building an interactive visualization workflow in KNIME typically involves using nodes that generate visualizations in formats that support interactivity, such as HTML or JavaScript-based charts. This would involve connecting data manipulation nodes to nodes capable of producing interactive visualizations. For instance, a workflow could start with data cleaning and transformation nodes, followed by a “Group By” node for aggregation, and then a node capable of generating an interactive HTML chart.
This interactive chart could then be viewed within KNIME or exported as an independent HTML file for sharing. The interactive nature allows users to zoom, pan, and select specific data points, facilitating a more thorough exploration of the data. Imagine an interactive map displaying sales data for different regions, where clicking on a region provides detailed sales information for that area.
This exemplifies the power of interactive visualizations in KNIME.
Deployment and Automation with KNIME
Okay, so you’ve built this awesome KNIME workflow, maybe even a whole suite of them. Now what? You don’t want to manually run it every time new data rolls in, right? That’s where deployment and automation come in – turning your analytical prowess into a self-service, always-on data processing machine. We’ll cover how to get your KNIME workflows out of the development environment and into the real world.Deploying KNIME workflows for automated data processing involves several key steps, starting with packaging your workflow for execution outside the KNIME Analytics Platform.
This often involves creating an executable workflow that can be run independently, potentially with minimal dependencies. Then, you choose your deployment strategy: embedding the workflow into an application, deploying to a server, or using cloud-based solutions. The choice depends on factors like scalability needs, security requirements, and existing infrastructure. Finally, setting up scheduling and monitoring ensures the workflow runs reliably and alerts you to any issues.
KNIME Server for Workflow Scheduling and Automation
KNIME Server provides a centralized platform for managing and executing KNIME workflows. It allows you to schedule workflows to run at specific times or intervals, triggered by events, or based on data availability. This is crucial for automating repetitive tasks and ensuring timely data processing. Imagine a scenario where you need to process daily sales data, generate reports, and send alerts if sales fall below a certain threshold.
KNIME Server handles all of this automatically, freeing up your time for more strategic work. You define the workflow, set the schedule, and let KNIME Server take care of the rest. It also provides detailed logging and monitoring capabilities, allowing you to track the workflow’s execution and identify any potential problems.
Sharing and Collaborating on KNIME Projects
KNIME Server also facilitates collaboration by enabling multiple users to access, share, and manage workflows. You can create different user roles and permissions to control access and maintain data security. This makes it ideal for team projects, allowing data scientists and analysts to work together efficiently. Version control capabilities help manage workflow changes and ensure everyone is working with the latest version.
Imagine a team working on a customer churn prediction model. With KNIME Server, they can collaborate on the model development, test different approaches, and deploy the final model without stepping on each other’s toes. Different team members can contribute to different parts of the workflow, making the entire process more efficient and less prone to errors.
Automating a Specific Data Analysis Task with KNIME Server
Let’s say we want to automate a simple sentiment analysis task. We have a daily influx of customer reviews from a website, and we want to automatically categorize them as positive, negative, or neutral. We’ll use a KNIME workflow with a text processing node (like the “Tokenizer” and “Sentiment Analysis” nodes) to analyze the reviews and a database node to store the results.
In KNIME Server, we would schedule this workflow to run daily at midnight. The workflow would automatically download the new reviews, perform the sentiment analysis, and update the database. The results could then be used to generate daily reports or trigger alerts based on changes in sentiment. This automated process saves time, improves efficiency, and provides real-time insights into customer feedback.
KNIME Server’s monitoring features would also alert us if the workflow fails, allowing us to quickly address any issues.
KNIME’s Strengths and Weaknesses

KNIME, while a powerful open-source data science platform, isn’t without its quirks. Comparing it to other platforms like RapidMiner and Orange reveals both its advantages and areas needing improvement. This section dives into KNIME’s strengths and weaknesses, exploring its suitability for various data analysis tasks and considering its learning curve and user interface.
KNIME Compared to Other Platforms
KNIME distinguishes itself through its visual workflow approach, making it relatively intuitive for beginners compared to purely code-based solutions. This contrasts with platforms like RapidMiner, which also offers a visual interface but can sometimes feel more complex for initial users. Orange, on the other hand, leans towards a more streamlined and simplified interface, making it ideal for quick exploratory data analysis but potentially limiting its power for large-scale or complex projects.
KNIME sits in the middle, offering a balance between visual simplicity and advanced functionality. RapidMiner boasts a strong enterprise focus with robust features for deployment and collaboration, whereas Orange excels in its user-friendliness and readily available visualization tools. KNIME’s strength lies in its extensibility and large community support, allowing for customization and integration with various tools and technologies.
Advantages and Disadvantages of KNIME for Different Data Analysis Tasks
KNIME’s modular nature makes it adaptable to diverse tasks. For data preprocessing and cleaning, its extensive node library provides efficient tools for handling missing values, transforming data types, and feature engineering. However, for extremely large datasets, its performance might lag behind specialized tools optimized for distributed computing. In machine learning, KNIME offers a broad range of algorithms and readily integrates with popular machine learning libraries like scikit-learn.
Yet, for highly specialized machine learning tasks or deep learning projects requiring fine-grained control over model architecture, dedicated deep learning frameworks might be more suitable. Data visualization in KNIME is powerful but can be less polished than dedicated visualization tools like Tableau or Power BI, particularly when generating interactive dashboards. For deployment and automation, KNIME’s server capabilities offer a streamlined process, although setting up and managing the server might present a challenge for users unfamiliar with server administration.
KNIME’s Learning Curve and User Interface
KNIME’s visual workflow paradigm generally makes it easier to learn than programming-centric approaches. The drag-and-drop interface and extensive documentation provide a good starting point for beginners. However, mastering the vast library of nodes and understanding their interactions requires time and practice. The interface itself, while visually appealing, can become cluttered with complex workflows, making navigation and debugging challenging for large projects.
The steepness of the learning curve depends heavily on prior experience with data science concepts and programming. A user with some programming background might find it easier to grasp the underlying logic and integrate custom code, while someone with no prior experience might need more time to familiarize themselves with the nodes and their functionalities. Effective training materials and community support significantly mitigate this learning curve.
Suggestions for Improving KNIME
To further enhance KNIME, several improvements could be considered. Firstly, optimizing performance for extremely large datasets is crucial. This could involve incorporating distributed computing capabilities more seamlessly or offering better integration with cloud-based computing resources. Secondly, improving the user interface for managing complex workflows, perhaps through improved visual organization tools or enhanced debugging capabilities, would enhance usability.
Finally, expanding the library of pre-built nodes for specific advanced analytics tasks, such as advanced time series analysis or natural language processing, would make KNIME even more versatile and attractive to a broader range of users.
Case Studies of KNIME Applications
KNIME’s versatility shines through in its diverse real-world applications. Across various sectors, businesses leverage KNIME’s capabilities to tackle complex data challenges and achieve significant improvements in efficiency and decision-making. The following case studies illustrate the breadth and depth of KNIME’s impact.
KNIME in Pharmaceutical Research and Development
In pharmaceutical research, KNIME is frequently used for drug discovery and development. Researchers employ KNIME to analyze large datasets of chemical compounds, biological assays, and clinical trial data to identify potential drug candidates, predict their efficacy, and optimize their design. For instance, a pharmaceutical company might use KNIME to analyze genomic data to identify potential drug targets for a specific disease, then utilize predictive modeling to assess the effectiveness of different drug candidates.
This streamlined workflow significantly reduces the time and cost associated with traditional drug discovery methods, leading to faster time-to-market for new medications.
KNIME in Financial Modeling and Risk Management
The financial industry relies heavily on data analysis for risk assessment, fraud detection, and algorithmic trading. KNIME’s powerful data manipulation and machine learning capabilities are well-suited to these tasks. A bank, for example, might use KNIME to build a model that predicts customer churn based on historical transaction data and demographic information. This allows the bank to proactively identify at-risk customers and implement targeted retention strategies.
Similarly, KNIME can be used to develop sophisticated fraud detection systems by analyzing transaction patterns and identifying anomalies indicative of fraudulent activity. The outcome is improved risk management and reduced financial losses.
KNIME in Marketing Analytics and Customer Segmentation
Marketing teams use KNIME to analyze customer data and optimize marketing campaigns. By integrating data from various sources, such as CRM systems, website analytics, and social media, marketers can gain a comprehensive understanding of customer behavior and preferences. A retail company might use KNIME to segment its customer base based on purchasing patterns and demographics, allowing for targeted marketing campaigns and personalized recommendations.
This results in improved customer engagement and increased sales conversions.
Case Study Table
| Industry | Application | Outcome |
|---|---|---|
| Pharmaceuticals | Drug discovery and development; analyzing genomic data, predicting drug efficacy | Faster time-to-market for new medications, reduced R&D costs |
| Finance | Risk management, fraud detection, algorithmic trading; customer churn prediction, anomaly detection | Improved risk management, reduced financial losses, enhanced trading strategies |
| Retail | Marketing analytics, customer segmentation; targeted marketing campaigns, personalized recommendations | Improved customer engagement, increased sales conversions |
| Manufacturing | Predictive maintenance, quality control; optimizing production processes, reducing downtime | Increased efficiency, reduced production costs, improved product quality |
Advanced KNIME Techniques
KNIME’s power truly shines when tackling complex data analysis scenarios. Beyond the basics, KNIME offers a robust environment for sophisticated techniques, allowing users to delve into intricate data structures and advanced modeling methods. This section explores some of these capabilities, demonstrating how KNIME can handle sophisticated analytical challenges.
Time Series Analysis in KNIME
KNIME provides several nodes for effective time series analysis. The “Time Series” extension offers tools for tasks such as forecasting, anomaly detection, and feature extraction. For example, you can use the “Moving Average” node to smooth out noisy time series data, revealing underlying trends. The “ARIMA” node allows for building sophisticated autoregressive integrated moving average models, useful for forecasting future values based on past observations.
These models can be applied to a wide range of applications, from predicting stock prices to analyzing sensor data. Visualization nodes can then be used to easily compare the predicted values to the actual values, allowing for quick assessment of model accuracy. Furthermore, the integration with R and Python allows for the implementation of more specialized time series algorithms not directly available within KNIME’s core functionality.
Network Analysis with KNIME
Analyzing network data, such as social networks or biological pathways, requires specialized techniques. KNIME offers various nodes and extensions to facilitate this. The “Network Analysis” extension provides nodes for creating network graphs from relational data, calculating centrality measures (like degree centrality or betweenness centrality), and detecting communities within the network. For example, a social network dataset can be analyzed to identify influential users based on their centrality scores.
Visualization nodes can then be used to represent the network graphically, highlighting key nodes and communities. The flexibility of KNIME allows for seamless integration with other analytical techniques; for instance, machine learning models can be used to predict links in a network based on node attributes.
Deep Learning in KNIME
KNIME seamlessly integrates with deep learning frameworks like TensorFlow and Keras. The “Deep Learning – Keras Integration” extension allows users to build and train deep learning models directly within the KNIME environment. This eliminates the need to switch between different tools, simplifying the workflow. Users can construct various neural network architectures, including convolutional neural networks (CNNs) for image processing and recurrent neural networks (RNNs) for sequential data.
For instance, a CNN could be trained to classify images, while an RNN might be used for natural language processing tasks. The model training process is managed within KNIME, providing easy access to performance metrics and allowing for hyperparameter tuning. The trained models can then be deployed within KNIME workflows for real-time predictions.
Scripting in KNIME Workflows
KNIME’s extensibility is further enhanced by its support for scripting languages like R and Python. The “R-Snippets” and “Python Script (Jython)” nodes allow users to incorporate custom code into their workflows, adding flexibility and power. This is particularly useful for implementing advanced algorithms or custom data preprocessing steps. For example, a Python script could be used to perform complex data cleaning or feature engineering tasks not readily available in standard KNIME nodes.
Similarly, R’s rich statistical capabilities can be leveraged for advanced statistical modeling. This integration of scripting empowers users to tailor KNIME to their specific needs, extending its capabilities far beyond its pre-built functionalities.
KNIME Community and Resources
Okay, so you’ve learned the basics of KNIME – now let’s talk about how to keep learning and get help when you’re stuck. The KNIME community is a huge asset, and understanding its resources is key to maximizing your KNIME experience. Think of it as your personal support network for all things data science within the KNIME ecosystem.The KNIME community offers a wealth of resources to help users of all skill levels.
From beginner tutorials to advanced workflows shared by experts, the community plays a vital role in both learning and troubleshooting. Active participation fosters collaboration and continuous improvement of the platform itself.
KNIME Forum
The KNIME forum is the central hub for community interaction. It’s where you can ask questions, share solutions, and engage in discussions with other KNIME users and even the KNIME team itself. Think of it as a giant, constantly updated FAQ, powered by real people. You can search for existing threads addressing similar problems, saving you time and effort.
If you don’t find an answer, posting your question is encouraged – the community is generally very responsive and helpful. The forum’s search functionality is pretty robust, so use s related to your specific issue to find relevant discussions.
KNIME Documentation
The official KNIME documentation is a comprehensive resource covering all aspects of the platform. It includes detailed explanations of nodes, workflows, and extensions, along with tutorials and examples. This is your go-to resource for understanding the technical details of KNIME’s functionalities. It’s organized logically and includes a good search function, making it easy to find the specific information you need.
Don’t underestimate the power of the search bar – it’s your best friend when navigating the documentation.
KNIME Examples
KNIME offers a vast library of example workflows that showcase various techniques and applications. These examples are readily available and can be imported directly into your KNIME workspace. This allows you to learn by doing, experimenting with different approaches, and adapting the workflows to your own projects. Many examples demonstrate best practices, helping you to build efficient and robust workflows.
By exploring these examples, you gain practical experience and discover new possibilities.
KNIME Hub
KNIME Hub is a repository where users can share and discover workflows, extensions, and other KNIME-related resources. It’s like a giant, collaborative cookbook of data science recipes. You can find solutions for specific tasks, learn from others’ approaches, and contribute your own workflows to help the community. Think of it as a vast library of pre-built components and solutions you can adapt and reuse in your own projects.
It’s a great place to find inspiration and accelerate your workflow development.
Effective Use of Community Resources
To effectively use the KNIME community resources, it’s helpful to formulate your questions clearly and concisely. Provide relevant context, including screenshots or sample data if necessary. Engage respectfully with other community members, acknowledging their contributions and offering your own insights when possible. Remember to search the forum and documentation thoroughly before posting a new question to avoid redundancy.
Participating actively in the community, by answering questions and sharing your own knowledge, will help you learn and grow alongside others. The more you contribute, the more you gain from the experience.
Ending Remarks
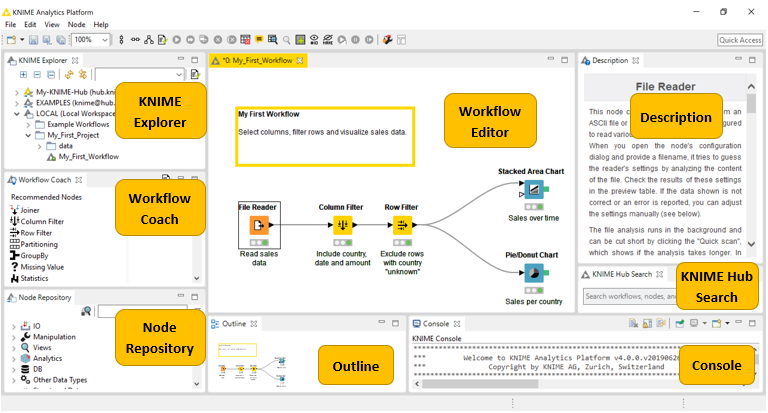
So, there you have it – a whirlwind tour of Knime’s capabilities. From its user-friendly interface to its robust functionality, Knime empowers both beginners and seasoned data scientists to tackle complex challenges with ease. Whether you’re a student crunching numbers for a research project or a data scientist building a production-ready model, Knime provides the tools and flexibility you need to succeed.
Now go forth and conquer your data!
FAQ Compilation
Is Knime free?
Knime Analytics Platform is free for personal and academic use. There are also commercial licenses available for businesses.
How steep is the Knime learning curve?
Knime’s visual workflow approach makes it relatively easy to learn, even for beginners. Plenty of online resources and tutorials are available to help you get started.
What types of data can Knime handle?
Knime supports a wide range of data types and formats, including CSV, Excel, databases (SQL, NoSQL), and cloud storage (like AWS S3).
Can I integrate Knime with my existing tools?
Absolutely! Knime integrates seamlessly with many popular tools, including R, Python, and various databases. You can even use it to automate tasks within your existing workflows.
Where can I get help if I get stuck?
The Knime community is very active and helpful. You can find tons of support on their forums, documentation, and through online tutorials.